1. Architecture¶
This document describes the current architecture that guides the platform implementation, detailing the components that comprise the solution, as well as their functionalities and how each of them contribute to the platform as a whole.
While a brief explanation of each component is provided, this high level description does not explain (or aims to explain) the minutiae of each component’s implementation. For that, please refer to each component’s own documentation.
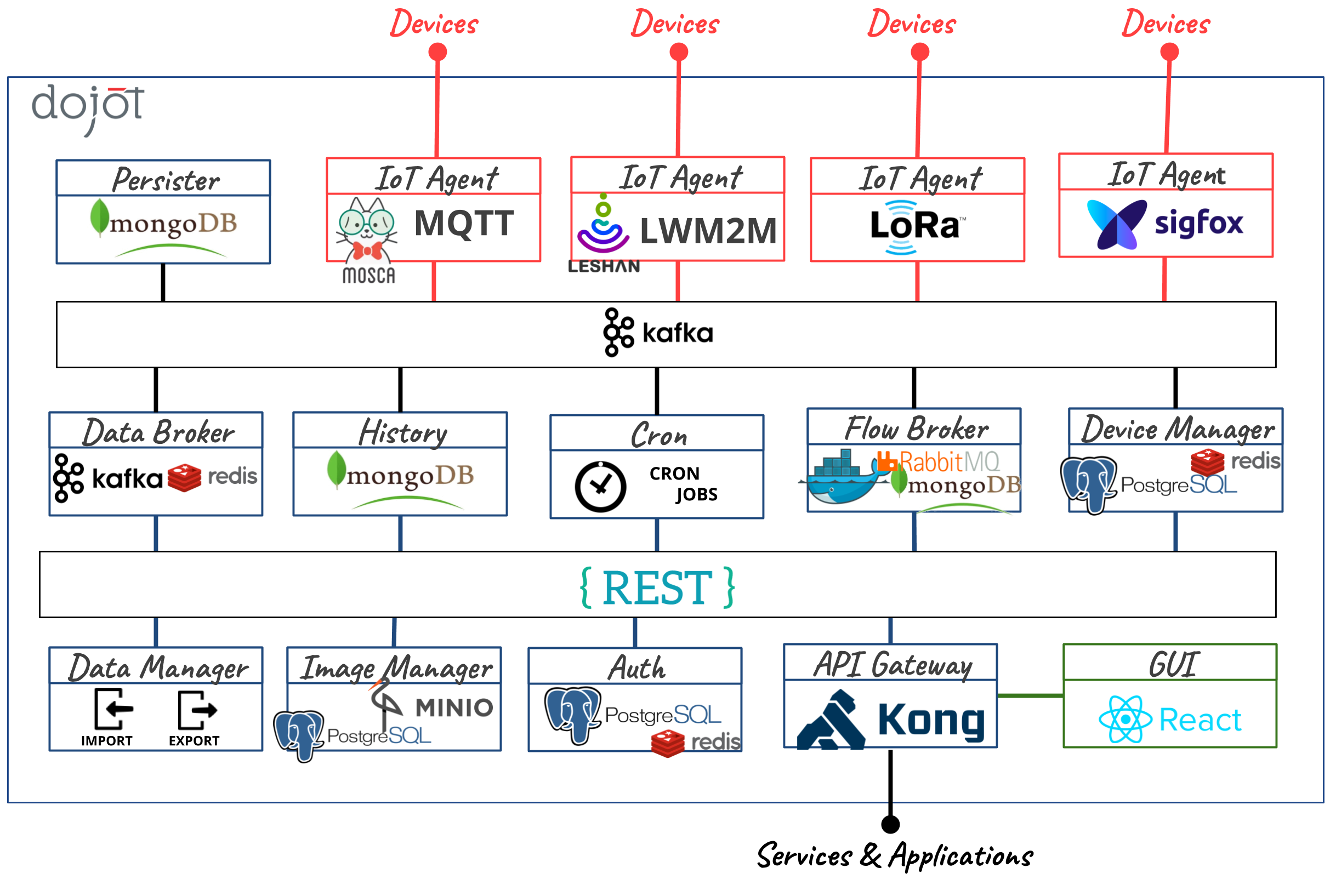
Fig. 1.1 : The microservice architecture of dojot platform.¶
A big picture of the whole architecture is shown in the figure above and in the following sections more details are given about each component.
Table of Contents
1.1. Components¶
Dojot was designed to make fast solution prototyping possible, providing a platform that’s easy to use, scalable and robust. Its internal architecture makes use of many well-known open-source components with others designed and implemented by dojot team.
Using dojot is as follows: a user configures IoT devices through the GUI or directly using the REST APIs provided by the API Gateway. Data processing flows might be also configured - these entities can perform a variety of actions, such as generate notifications when a particular device attribute reaches a certain threshold or send data generated by a device to an external service. As devices start sending their readings to dojot, a user can:
receive these readings in real time by socket.io or websocket channels;
consolidate all data into virtual devices;
gather all data from historical database, and so on.
These features can be used through REST APIs - these are the basic building blocks that any application based on dojot should use. dojot GUI provides an easy way to perform management operations for all entities related to the platform (users, devices, templates and flows) and can also be used to check if everything is working fine.
The tenant contexts are isolated and there are no data sharing, the access credentials are validated by the authorization service for each and every operation (API Request). Therefore, a user belonging to a particular context (tenant) cannot reach any data (including devices, templates, flows or any other data related to these resources) from other ones.
Once devices are configured, the IoT Agent is capable of mapping the data received from devices, encapsulated on MQTT for example, and send them to the message broker for internal distribution. This way, the data reaches the persistence service, for instance, so it can persist the data on a database.
For more information about what’s going on with dojot, you should take a look at dojot GitHub repository. There you’ll find all components used in dojot.
Each one of the components that are part of the architecture are briefly described on the sub-sections below.
1.1.1. Kafka + DataBroker¶
Apache Kafka is a distributed messaging platform that can be used by applications which need to stream data or consume/produce data pipelines. In comparison with other open-source messaging solutions, Kafka seems to be more appropriate to fulfil dojot’s architectural requirements (responsibility isolation, simplicity, and so on).
In Kafka, a specialized topics structure is used to insure isolation among different tenants and applications data, enabling a multi-tenant infrastructure.
The DataBroker service makes use of an in-memory database for efficiency. It adds context to Apache Kafka, making it possible that internal or even external services are able to consume real-time data based on context. DataBroker can also be a distributed service to avoid it being a single point of failure or even a bottleneck for the architecture.
1.1.2. DeviceManager¶
DeviceManager is a core entity which is responsible for keeping devices and templates data models. It is also responsible for publishing any updates to all interested components through Kafka.
This service is stateless, having its data persisted to a database, with data isolation for tenants and applications, making possible a multi-tenant architecture for the middleware.
1.1.3. IoT Agent¶
An IoT agent is an adaptation service between physical devices and dojot’s core components. It could be understood as a device driver for a set of devices. The dojot platform can have multiple iot-agents, each one of them being specialized in a specific protocol like, for instance, MQTT/JSON, CoAP/LWM2M, Lora/ATC, Sigfox/WDN and HTTP/JSON.
Communication via secure channels with devices is also the responsibility of IoT agents.
1.1.4. User Authorization Service¶
This service is responsible for managing user profiles and access control. Basically any API call that reaches the platform via the API Gateway is validated by this service.
To be able to deal with a high volume of authorization calls, it uses caching, it is stateless and it is scalable horizontally. Its data is stored on a database.
1.1.5. Flowbroker (Flow builder)¶
This service provides mechanisms to build data processing flows to perform a set of actions. These flows can be extended using external processing blocks (which can be added using REST APIs).
1.1.6. Data Manager¶
This service manages the dojot’s data configuration, making possible to import and export configuration like templates, devices and flows.
1.1.7. Cron¶
Cron is a dojot’s microservice that allows you to schedule events to be emitted - or requests to be sent - to other microservices inside dojot platform.
1.1.8. Kafka2Ftp¶
The kafka2ftp service allows forwarding messages from Apache Kafka
to FTP servers. It subscribes to Kafka’s topic tenant.dojot.ftp, where the
messages must follow a specific schema. Messages can be redirected to these
topics using a specific node in the flowbroker.
1.1.9. Persister/History¶
The Persister component works as a pipeline for data and events that must be persisted on a database. The data is converted into a storage structure and is sent to the corresponding database.
For internal storage, the MongoDB non-relational database is being used, it allows a Sharded Cluster configuration that may be required according to the use case.
The persisted data can be queried through a Rest API provided by the History microservice.
1.1.10. InfluxDB Storer and Retriever¶
The services InfluxDB Storer and InfluxDB Retriever work together, the InfluxDB Storer is responsible for consuming Kafka data from dojot devices and writing it to InfluxDB, while the InfluxDB Retriever has the role of obtaining the data that were written by InfluxDB Storer in InfluxDB via API REST.
1.1.11. Kong API Gateway¶
The Kong API Gateways is used as the entry point for applications and external services to reach the services that are internal to the dojot platform, resulting in multiple advantages like, for instance, single access point and ease when applying rules over the API calls like traffic rate limitation and access control.
1.1.12. GUI¶
The Graphical User Interface in dojot is responsible for providing responsive interfaces to manage the platform, including functionalities like:
User Profile Management: Define profiles and the API permission associated to those profiles
User Management: Creation, Visualization, Edition and Deletion Operations
Templates Management: Creation, Visualization, Edition and Deletion Operations
Devices Management: Creation, Visualization (real time data), Edition and Deletion Operations
Processing Flows Management: Creation, Visualization, Edition and Deletion Operations
Notifications: View system notifications (unified real time and history)
1.1.13. Image manager¶
This component is responsible for device (firmware) image storage and retrieval. It is used by the firmware update mechanism.
1.1.14. X.509 Identity Management¶
This component is responsible for assigning identities to devices, such identities are represented in the form of x.509 certificates. It behaves similarly to a Certificate Authority (CA), where it is possible to submit a CSR and receive a certificate back. Once the certificate has been installed on the device, it is possible to communicate securely with the dojot platform, as the data collected by the device is transmitted over a secure (encrypted) channel and it is also possible to guarantee the integrity of the data.
1.1.15. Kafka WS¶
This component is responsible for retrieving data from Apache Kafka through pure WebSocket connections. It was designed to allow dojot users to retrieve realtime raw and/or processed data from dojot devices.
1.2. Infrastructure¶
A few extra components are used in dojot,they are:
postgres: this database is used to persist data from many components, such as Device Manager.
redis: in-memory database used as cache in many components, such as service orchestrator, subscription manager, IoT agents, and so on. It is very light and easy to use.
rabbitMQ: message broker used in service orchestrator in order to implement action flows related that should be applied to messages received from components.
mongo database: widely used database solution that is easy to use and doesn’t add a considerable access overhead (where it was employed in dojot).
zookeeper: keeps replicated services within a cluster under control.
1.3. Communications¶
All components communicate with each other in two ways:
Using HTTP requests: if one component needs to retrieve data from other one, say an IoT agent needs the list of currently configured devices from Device Manager, it can send a HTTP request to the appropriate component.
Using Kafka messages: if one component needs to send new information about a resource controlled by it (such as new devices created in Device Manager), the component may publish this data through Kafka. Using this mechanism, any other component that is interested in such information needs only to listen to a particular topic to receive it. Note that this mechanism doesn’t make any hard associations between components. For instance, Device Manager doesn’t know which components need its information, and an IoT agent doesn’t need to know which component is sending data through a particular topic.